|
Chen-Tao Lee I am a research assistant at Academia Sinica, working in the Computer System Lab under the guidance of Prof. Jan-Jan Wu and Ding-Yong Hong on the co-design of software and hardware for ML accelerators. Previously, I conducted research with Prof. Shao-Hua Sun at the NTU Robot Learning Lab, where I focused on integrating program synthesis with reinforcement learning (RL) to develop interpretable policies capable of addressing long-horizon robotic tasks. My research centers on designing explainable and efficient AI systems that can generalize to unseen scenarios while ensuring fast inference and training speeds. I received my B.S. in Electrical Engineering and B.A. in Finance from National Taiwan University in 2023. Email / CV / Google Scholar / Github |

|
Research
|
|
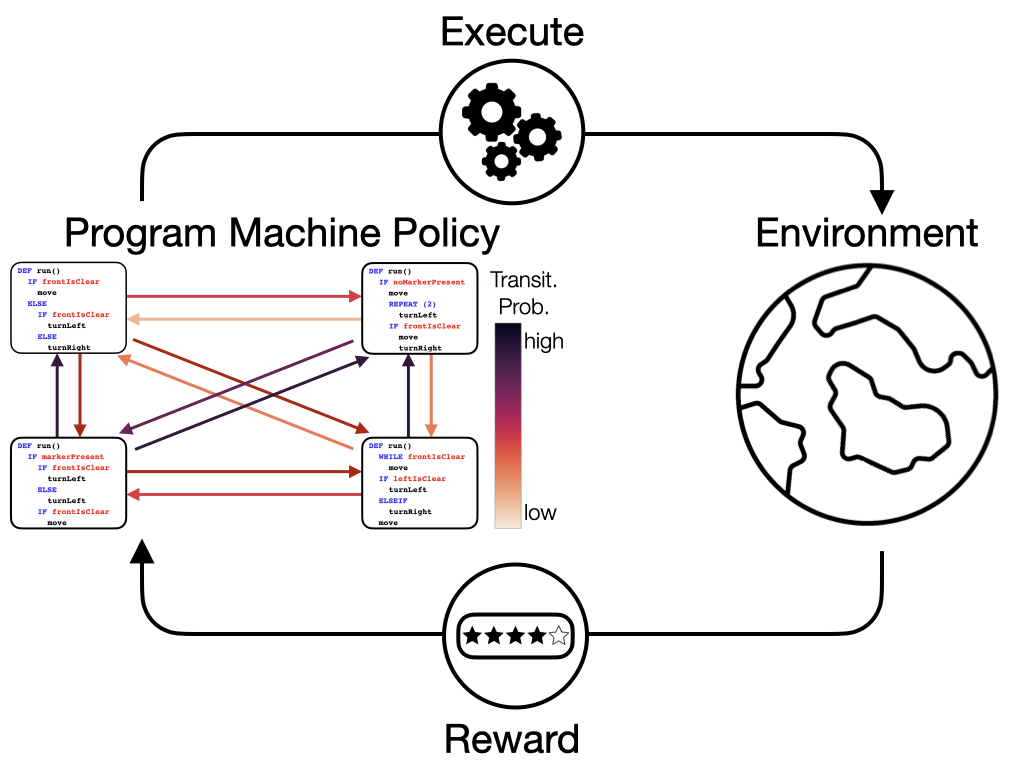
Hierarchical Programmatic Option Framework
Yu-An Lin*, Chen-Tao Lee*, Chih-Han Yang*, Guan-Ting Liu*, Shao-Hua Sun (Equal contribution) Neural Information Processing Systems (NeurIPS), 2024 Deep reinforcement learning aims to learn deep neural network policies to solve large-scale decision-making problems. However, approximating policies using deep neural networks makes it difficult to interpret the learned decision-making process. To address this issue, prior works (Trivedi et al., 2021; Liu et al., 2023; Carvalho et al., 2024) proposed to use human-readable programs as policies to increase the interpretability of the decision-making pipeline. Nevertheless, programmatic policies generated by these methods struggle to effectively solve long and repetitive RL tasks and cannot generalize to even longer horizons during testing. To solve these problems, we propose the Hierarchical Programmatic Option framework (HIPO), which aims to solve long and repetitive RL problems with human-readable programs as options (low-level policies). Specifically, we propose a method that retrieves a set of effective, diverse, and compatible programs as options. Then, we learn a high-level policy to effectively reuse these programmatic options to solve reoccurring subtasks. Our proposed framework outperforms programmatic RL and deep RL baselines on various tasks. Ablation studies justify the effectiveness of our proposed search algorithm for retrieving a set of programmatic options. |
|
Website source code from Jon Barron. |